Comment Fonctionne Google
Le fonctionnement de Google repose sur trois mécanismes distincts et séquentiels : l'exploration (crawl), l'indexation et le classement. Ces processus déterminent quelles pages apparaissent dans les résultats de recherche et dans quel ordre.
Comprendre ces mécanismes constitue un prérequis pour toute démarche d'optimisation pour les moteurs de recherche. Ce qu'on décrit ici est une simplification. Le système réel est plus complexe, avec des variations par pays, appareil, historique de recherche.
Exploration et crawl
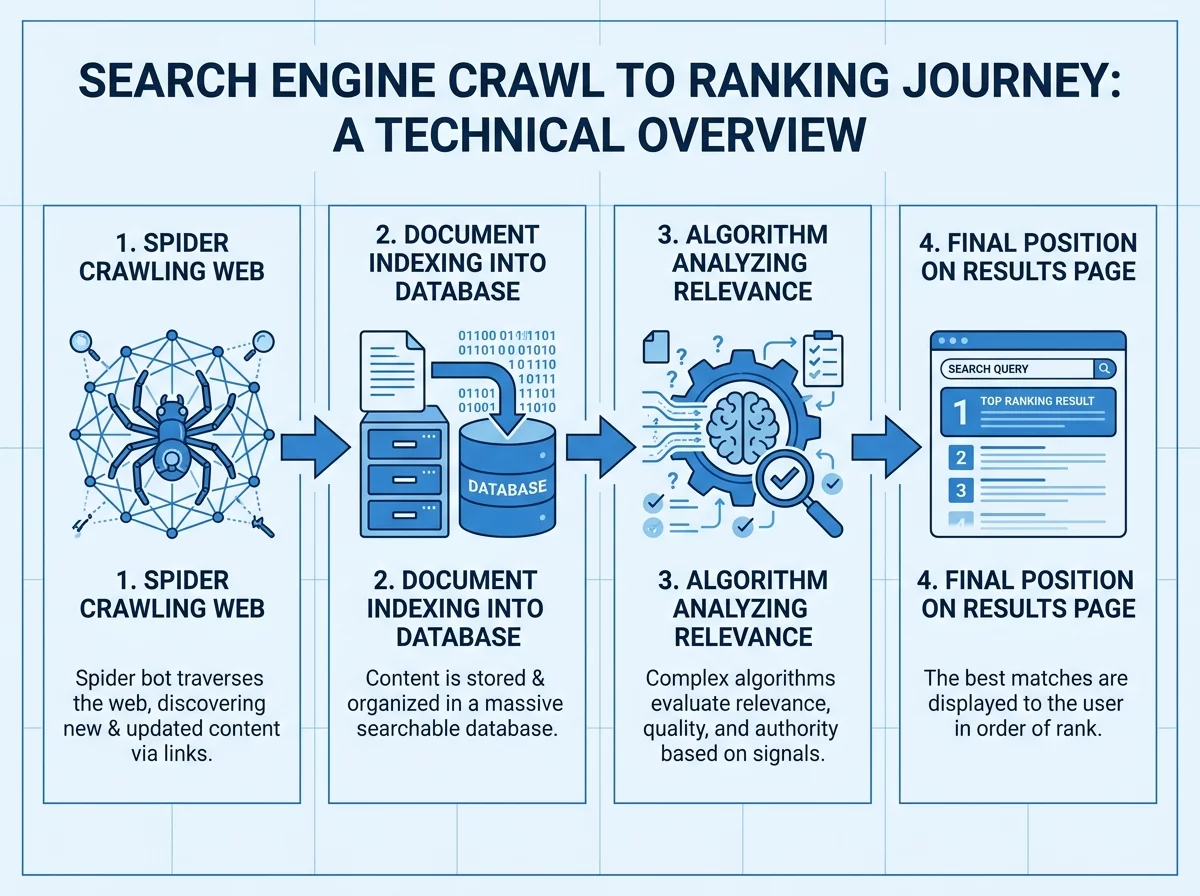
L'exploration désigne le processus par lequel Google découvre l'existence de pages web. Cette étape précède toute possibilité d'apparition dans les résultats de recherche.
Le robot Googlebot
Googlebot est le programme informatique (robot d'exploration ou crawler) utilisé par Google pour parcourir le web. Il visite les pages, suit les liens qu'il y trouve, et transmet les données collectées aux serveurs de Google pour analyse.
Googlebot existe en plusieurs versions : une pour le contenu desktop, une pour le contenu mobile. Depuis 2019, la version mobile (mobile-first indexing) est prioritaire pour la majorité des sites.
Comment il découvre vos pages
Googlebot découvre les pages de trois manières principales :
- En suivant les liens depuis des pages déjà connues
- Via les fichiers sitemap XML soumis dans Google Search Console
- Par soumission directe d'URL dans Search Console (inspection d'URL)
Un site client avait 50 000 pages. Google n'en crawlait que 2 000 par jour — budget crawl limité. On a élagué 30 000 pages inutiles. Résultat : les pages importantes crawlées 3 fois plus souvent.
Ce qui bloque le crawl
Plusieurs éléments peuvent empêcher Googlebot d'accéder au contenu :
- Directives dans le fichier robots.txt interdisant l'accès
- Pages nécessitant une authentification
- Erreurs serveur (codes 5xx) ou pages inexistantes (404)
- Temps de chargement excessif
- Contenu généré uniquement par JavaScript
Googlebot ne peut pas exécuter tous les JavaScript, ce qui rend invisible une partie du contenu des sites mal configurés — un problème touchant 23% des sites audités en 2023.
Indexation des pages
L'indexation est le processus de stockage et d'organisation des informations collectées lors du crawl. Une page indexée est une page que Google connaît et peut potentiellement afficher dans ses résultats.
De l'exploration à l'index
Après avoir crawlé une page, Google analyse son contenu : texte, images, vidéos, métadonnées. Ces informations sont traitées puis stockées dans l'index Google, une base de données massive contenant des centaines de milliards de pages.
L'index n'est pas une copie intégrale des pages. Google extrait et structure les informations pertinentes : mots-clés, entités mentionnées, liens, signaux de qualité.
Pourquoi certaines pages ne sont pas indexées
L'exploration ne garantit pas l'indexation. Google peut décider de ne pas indexer une page pour plusieurs raisons :
- Contenu dupliqué ou trop similaire à d'autres pages
- Qualité jugée insuffisante
- Balise meta noindex présente
- Page canonique pointant vers une autre URL
- Contenu trop mince (thin content)
Pour approfondir les bases du référencement naturel, consulter l'article dédié aux principes fondamentaux.
Algorithme de classement
Le classement détermine l'ordre d'apparition des pages dans les résultats pour une requête donnée. L'algorithme de Google évalue des centaines de signaux pour établir ce classement.
Les facteurs principaux
Google utilise plus de 200 facteurs de classement selon ses communications officielles, mais leur pondération exacte reste secrète et varie selon les requêtes.
Les catégories de facteurs documentées incluent :
- Pertinence du contenu : adéquation entre la page et l'intention de recherche
- Qualité du contenu : expertise, exhaustivité, originalité
- Expérience utilisateur : vitesse, compatibilité mobile, sécurité HTTPS
- Autorité : liens entrants, mentions, réputation du domaine
- Fraîcheur : pour les sujets où l'actualité compte
Les SEO passent trop de temps à deviner l'algorithme. Les fondamentaux (technique propre, contenu utile, liens légitimes) fonctionnent depuis 20 ans. Le reste est du bruit.
Le rôle du contexte utilisateur
Les résultats varient selon plusieurs paramètres contextuels :
- Localisation géographique de l'utilisateur
- Langue du navigateur et préférences
- Type d'appareil (mobile, desktop, tablette)
- Historique de recherche (si connecté à un compte Google)
Deux utilisateurs effectuant la même recherche peuvent obtenir des résultats différents. Cette personnalisation rend les comparaisons de positions complexes.
Ce qu'on ne sait pas
Malgré les communications officielles et les brevets publiés, de nombreux aspects restent opaques :
- Pondération exacte de chaque facteur
- Fonctionnement précis des systèmes d'apprentissage automatique (RankBrain, BERT, MUM)
- Seuils de déclenchement des filtres algorithmiques
- Interactions entre les différents signaux
Pour explorer les méthodes d'optimisation avancées, consulter la section dédiée aux techniques SEO.
Mises à jour majeures
L'algorithme de Google évolue en permanence. Certaines mises à jour ont marqué des tournants dans les pratiques de référencement.
Panda, Penguin, et les autres
Les mises à jour nommées ont ciblé des pratiques spécifiques :
- Panda (2011) : pénalisation du contenu de faible qualité, des fermes de contenu
- Penguin (2012) : ciblage des schémas de liens artificiels
- Hummingbird (2013) : meilleure compréhension du langage naturel
- Mobilegeddon (2015) : favorisation des sites mobile-friendly
- BERT (2019) : compréhension contextuelle des requêtes
Ces mises à jour ont conduit à des pénalités Google pour de nombreux sites utilisant des techniques manipulatoires. Pour plus de contexte historique, voir l'article Optimisation pour les moteurs de recherche sur Wikipédia.
Core Updates
Depuis 2018, Google déploie régulièrement des "Core Updates" — des mises à jour larges affectant l'évaluation globale de la qualité. Ces mises à jour ne ciblent pas un facteur spécifique mais réévaluent l'ensemble des signaux.
Google communique sur ces mises à jour via son compte Twitter @searchliaison et son blog officiel. Les effets peuvent prendre plusieurs semaines à se stabiliser.
Vérifier que Google peut explorer votre site
- ☐ Fichier robots.txt accessible et correct
- ☐ Sitemap XML soumis dans Search Console
- ☐ Pas de noindex sur les pages importantes
- ☐ Liens internes vers toutes les pages
- ☐ JavaScript non bloquant pour le contenu principal
Questions fréquentes
Google peut-il lire mon site en JavaScript ?
Partiellement. Googlebot exécute le JavaScript mais avec un délai et des limitations. Les contenus critiques doivent être accessibles en HTML initial pour garantir l'indexation.
Voir aussi
Notes et références
- Google Search Central - Documentation officielle sur le crawl et l'indexation
- Wikipédia - Optimisation pour les moteurs de recherche
- Google Search Liaison (@searchliaison) - Communications officielles sur les mises à jour